How AI Music Models Like Suno Work: Infrastructure & Training (Part 3)
AI-assisted, human-edited
This article was drafted with the help of large language models and reviewed by a Shine Soft Corp engineer before publication. Facts, citations, and code samples were verified against the linked sources. All opinions and editorial direction belong to the editor.
Discover how AI music platforms like Suno are built using GPUs, datasets, neural networks, training pipelines and large-scale music generation infrastructure.

Building Your Own AI Music Model: Infrastructure, Datasets, Training and Deployment Guide (Part 3)
SEO Title: How to Build an AI Music Model Like Suno: Infrastructure, Training, GPUs and Architecture Explained
Meta Description: Learn how AI music platforms like Suno are built. Explore music datasets, GPUs, training pipelines, inference systems, deployment architecture and infrastructure requirements.
Introduction
In Part 1 we learned how AI generates music.
In Part 2 we explored how AI understands genres, instruments, emotions and musical styles.
Now we move behind the curtain.
The question many developers, founders and AI enthusiasts ask is:
How would you build something like Suno?
What infrastructure is required?
How many GPUs?
What datasets?
What models?
How much would it cost?
This article explains the high-level architecture behind modern AI music generation systems.
The Dream vs Reality
Most people imagine AI music generation as:
Prompt → Music
But internally the system looks more like:
Prompt → Language Understanding → Music Planning → Melody Generation → Instrument Arrangement → Vocal Generation → Audio Synthesis → Mixing → Final Song
Modern AI music systems contain multiple specialized AI models working together.
The High-Level Architecture
![[Image: Modern AI music platform architecture showing Prompt → Language Model → Music Planner → Melody Generator → Vocal Generator → Audio Synthesizer → Final Song, futuristic enterprise diagram, OpenAI research style, 16:9]](https://media.shinesoftcorp.com/blog/cfe34da0-1a8d-45c9-ac48-2967f7d849ba.webp) A simplified architecture looks like:
A simplified architecture looks like:
User Prompt ↓ Language Model ↓ Music Planning Model ↓ Melody Generation ↓ Instrument Generation ↓ Vocal Generation ↓ Audio Rendering ↓ Final Track
Each stage solves a different problem.
Step 1: Understanding The Prompt
![[Image: AI interpreting music prompts, converting human language into musical instructions, futuristic neural network visualization, ultra realistic technology artwork, 16:9]](https://media.shinesoftcorp.com/blog/5a1fa485-74fd-4c9a-8b2a-10695198b116.webp) When a user writes:
When a user writes:
Create an emotional Bollywood love song with female vocals and cinematic strings.
The system must understand:
- Genre: Bollywood
- Mood: Emotional
- Vocals: Female
- Instruments: Strings
- Structure: Song
- Production Style: Cinematic
This stage is often powered by a Large Language Model (LLM).
The output is not music.
The output is a structured music plan.
Step 2: Music Planning Layer
Think of this as the "AI Composer."
It decides:
- Tempo
- Key
- Chord Progression
- Song Structure
- Instrument Palette
- Energy Curve
Example:
Verse → Chorus → Verse → Chorus → Bridge → Finale
The system now knows what kind of song it wants to build.
Step 3: Melody Generation

This is where actual musical creativity begins.
The model predicts:
- Main melody
- Counter melodies
- Hooks
- Musical motifs
This stage is similar to how language models predict words.
Music models predict notes.
Step 4: Instrument Generation
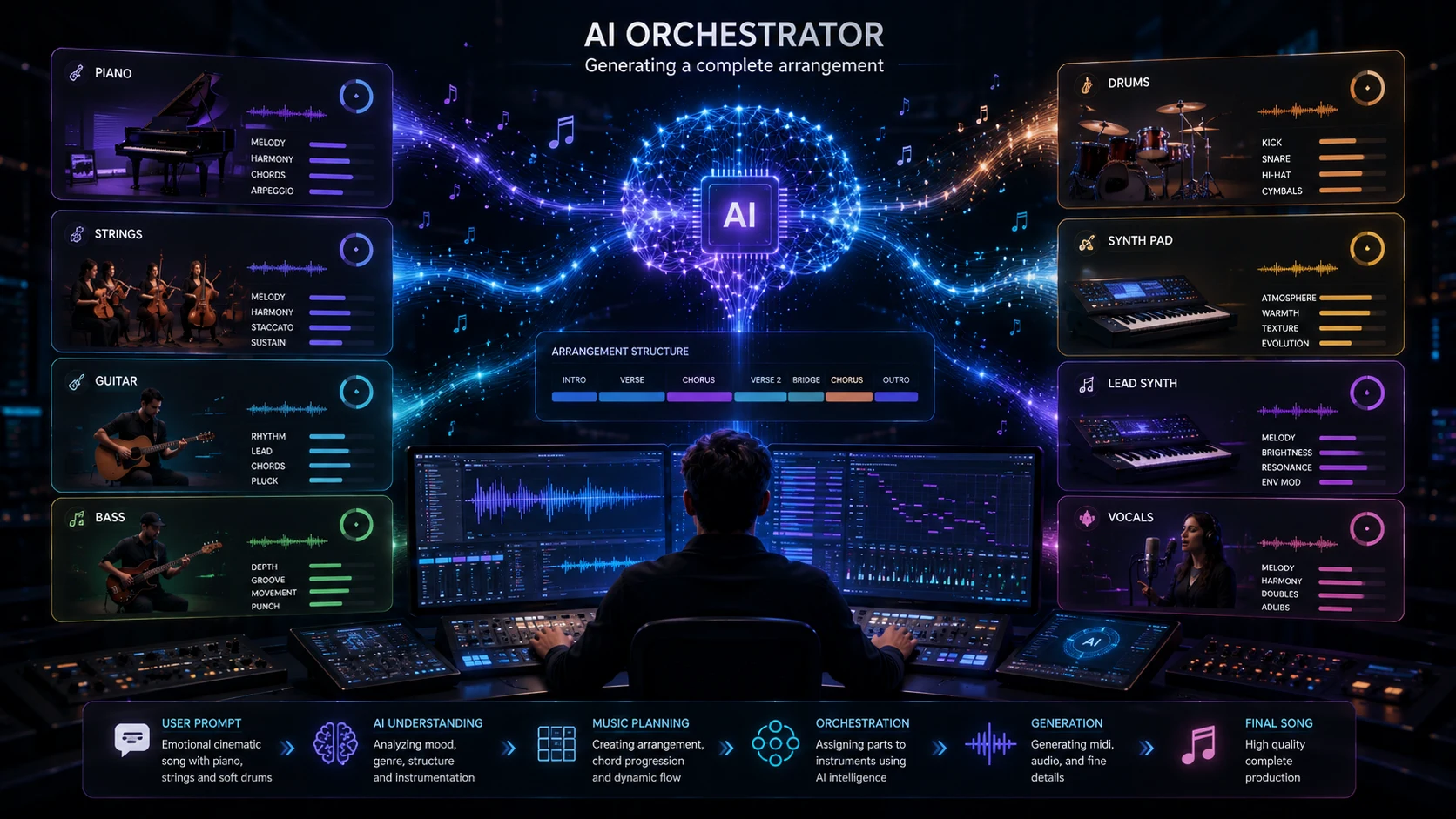
The system now decides:
- Piano patterns
- Guitar rhythm
- Drum arrangement
- Bass movement
- Orchestra layers
Different models may specialize in different instrument families.
Step 5: Vocal Generation

This is one of the hardest challenges.
The model must learn:
- Pronunciation
- Emotion
- Timing
- Breath control
- Singing style
Modern systems can generate:
- Male vocals
- Female vocals
- Choirs
- Harmonies
- Multiple languages
Step 6: Audio Synthesis
Text and notes are not enough.
Everything must become actual sound.
This stage converts abstract musical representations into waveforms.
The result:
- Vocals
- Instruments
- Atmosphere
- Effects
Combined into a playable audio track.
What Makes Suno Different?
Suno appears to combine multiple capabilities into one user experience:
- Prompt understanding
- Lyrics generation
- Vocal generation
- Music composition
- Audio synthesis
The user sees one button.
Behind the scenes, many systems likely work together.
The Data Problem
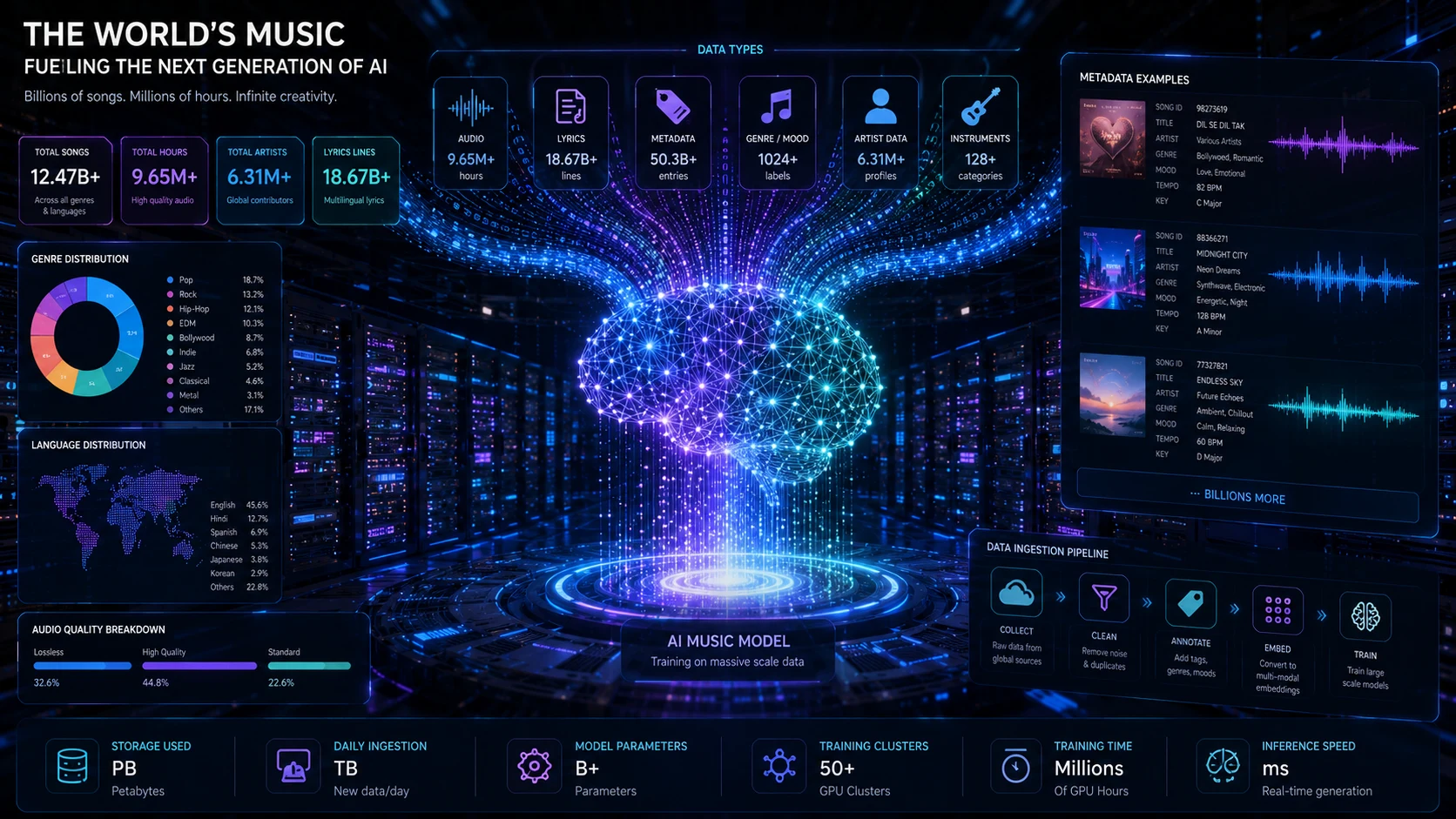
AI models learn from data.
A music company needs:
- Audio files
- Metadata
- Genre labels
- Tempo labels
- Instrument labels
- Lyrics
- Vocal annotations
Without data, there is no model.
The Compute Problem
Training music models requires enormous computing power.
Typical hardware:
- NVIDIA H100 GPUs
- NVIDIA B200 GPUs
- Multi-node GPU clusters
- High-speed networking
- Petabyte-scale storage
Training may run for:
- Weeks
- Months
Depending on model size.
Typical AI Music Infrastructure

Core components:
Training Cluster
- GPU servers
- Distributed training
Storage Layer
- Audio datasets
- Model checkpoints
Inference Layer
- User requests
- Real-time generation
Monitoring
- Quality tracking
- Cost tracking
- System health
Why Building Suno Is Difficult
Many startups underestimate the challenge.
You need expertise in:
- Machine Learning
- Audio Processing
- Music Theory
- Distributed Systems
- GPU Infrastructure
- Product Design
This is not just one AI model.
It is an ecosystem.
Cost Reality
A prototype can be built surprisingly cheaply.
A global-scale platform cannot.
Costs include:
- GPU compute
- Storage
- Model training
- Inference
- Licensing
- Engineering salaries
Scaling is often harder than training.
Open Source Alternatives
Several projects are helping democratize AI music.
Examples include:
- MusicGen
- AudioCraft
- Stable Audio
- Open-source audio transformers
These systems allow developers to experiment without building everything from scratch.
The Biggest Mistake Founders Make
Many founders focus on:
Generating music.
Successful companies focus on:
Building a complete music creation experience.
Users care about:
- Simplicity
- Speed
- Creativity
- Consistency
Not model architecture.
Key Takeaways
✅ AI music platforms use multiple specialized models.
✅ Music generation involves planning, composition, vocals and synthesis.
✅ Data quality matters as much as model size.
✅ GPUs are one of the largest costs.
✅ Building a global-scale platform requires far more than training a model.
What's Coming In Part 4
Now that we understand the architecture...
The next question becomes:
What datasets actually train these models?
In Part 4 we will explore:
- Music datasets
- Audio labeling
- Lyrics datasets
- Metadata systems
- Copyright challenges
- Dataset cleaning
- Building proprietary music datasets
- Why data quality beats data quantity
Next Article