Evaluating AI Agents Systematically with Agent-EvalKit
AI-assisted, human-edited
This article was drafted with the help of large language models and reviewed by a Shine Soft Corp engineer before publication. Facts, citations, and code samples were verified against the linked sources. All opinions and editorial direction belong to the editor.
Learn how to evaluate AI agents systematically with Agent-EvalKit, an open-source toolkit that integrates with AI coding assistants to provide a comprehensive evaluation infrastructure.


Evaluating AI Agents Systematically with Agent-EvalKit
Teams building AI agents typically evaluate them the way they evaluate any other software: by checking whether the output matches expectations. But agents that autonomously choose tools and sequence operations across multiple sources produce behavior that output-level testing cannot fully characterize.

An agent might deliver a well-structured, actionable response while hallucinating, fabricating facts because its tools returned empty results. It might also reach the correct conclusion while skipping the verification steps that a reliable process requires. Because these failures sit below the surface of the final response, catching them requires evaluation that traces the agent’s full execution path: which tools the agent called, what data those tools returned, and whether the response faithfully reflects that data.
Closing this gap requires infrastructure that most agent teams are not staffed to build from scratch. You need test cases with ground truth outcomes, observability instrumentation for capturing tool calls and intermediate state, and metrics that assess faithfulness and tool usage alongside surface accuracy.
🧠 What Agent Evaluation Requires
Beyond the infrastructure itself, choosing what to measure is equally demanding. Agent quality spans dimensions that no single metric captures: whether responses are grounded in what the tools actually returned, whether the agent called the right tools with the right parameters, and whether the final output is coherent and useful to the person asking. A response can read well while quietly hallucinating over empty tool results, and an agent can arrive at a plausible answer through a broken sequence of tool calls, so each dimension has to be checked on its own rather than inferred from the one next to it.
No single evaluator style handles all three well. Code-based evaluators offer fast, reproducible results but penalize valid variations in approach. Large language model (LLM) as judge evaluators provide nuanced assessment at the cost of additional inference and careful prompt design. Most effective evaluation strategies combine both approaches. Translating evaluation scores into concrete code changes is where many efforts ultimately stall, which is why an evaluation workflow needs to end in specific, code-level recommendations rather than a dashboard of numbers.
🧠 How Agent-EvalKit Works
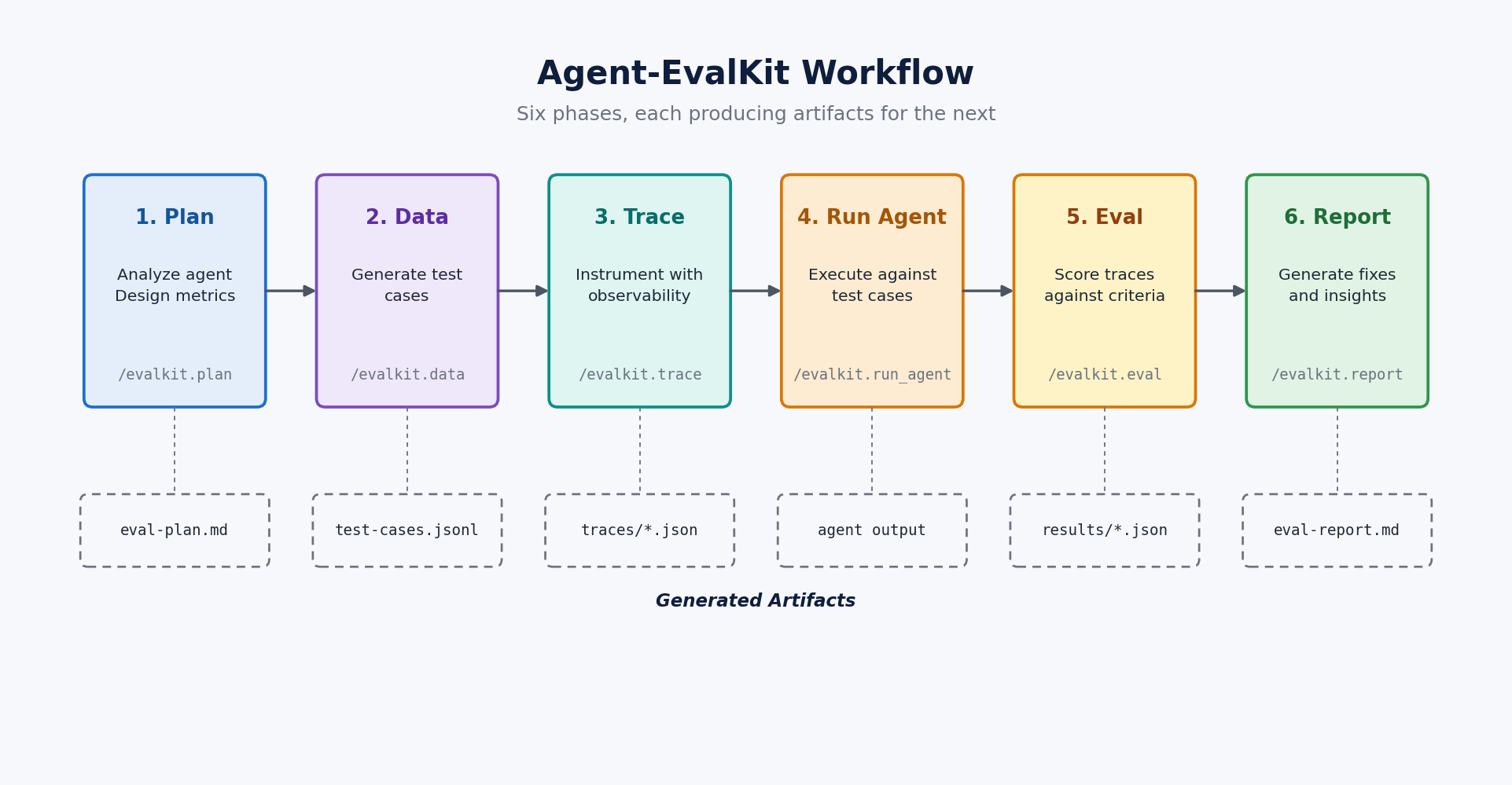
Agent-EvalKit works through your existing AI coding assistant instead of running as a separate evaluation platform. Your assistant, whether Claude Code, Kiro CLI, or Kilo Code, becomes the evaluation engine by applying its ability to read code and reason about agent behavior at each phase of the evaluation process. You drive this workflow through slash commands like /evalkit.plan and /evalkit.data , appending natural language guidance that tells the assistant what quality dimensions matter most for your agent.
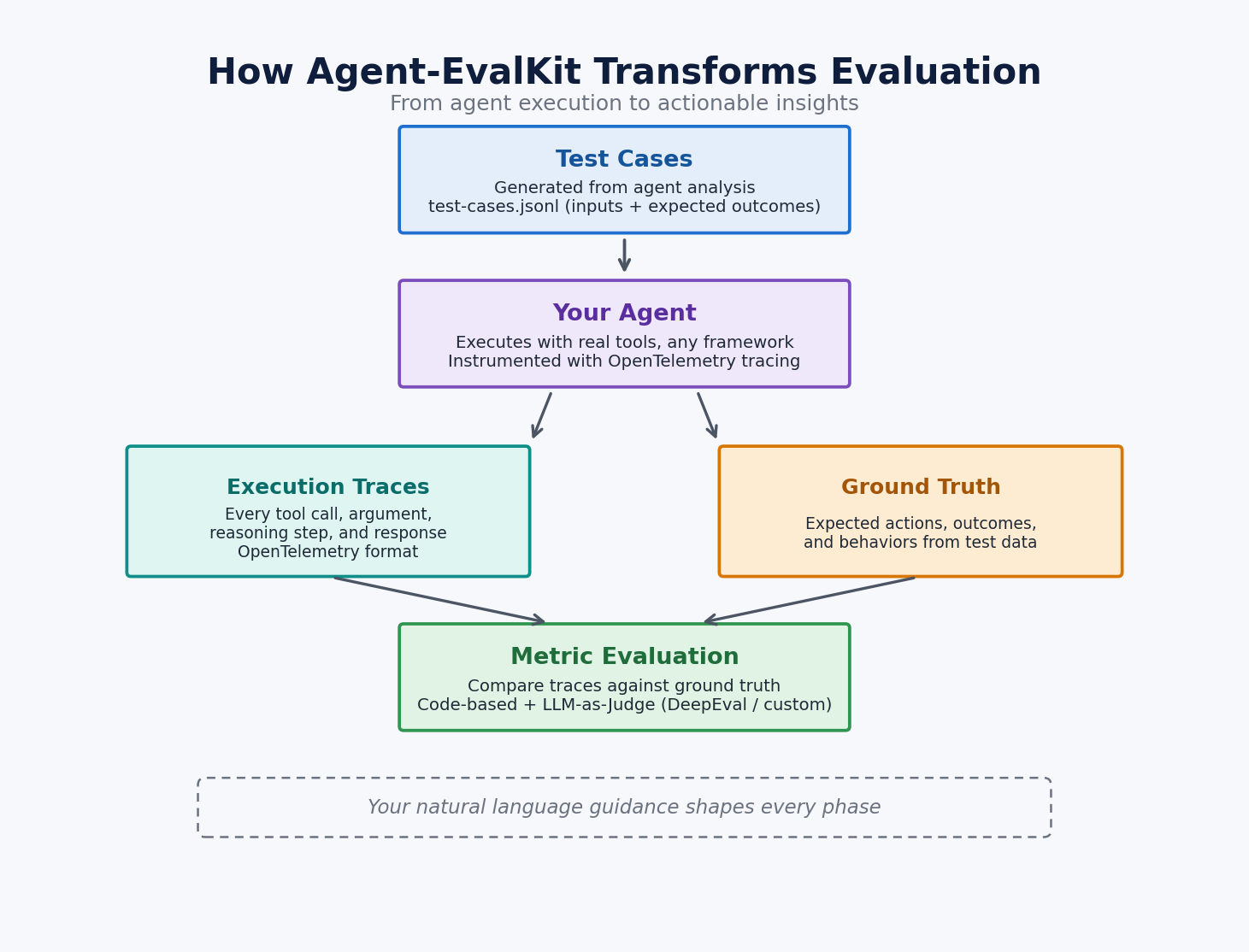
The process starts with your agent’s source code, where the assistant reads tool definitions, the system prompt, and framework configuration to build a detailed model of what your agent does, which tools it can call, and where its behavior might break down. Every artifact the toolkit produces in subsequent phases, from the evaluation plan through the final report, builds on this code-level understanding.
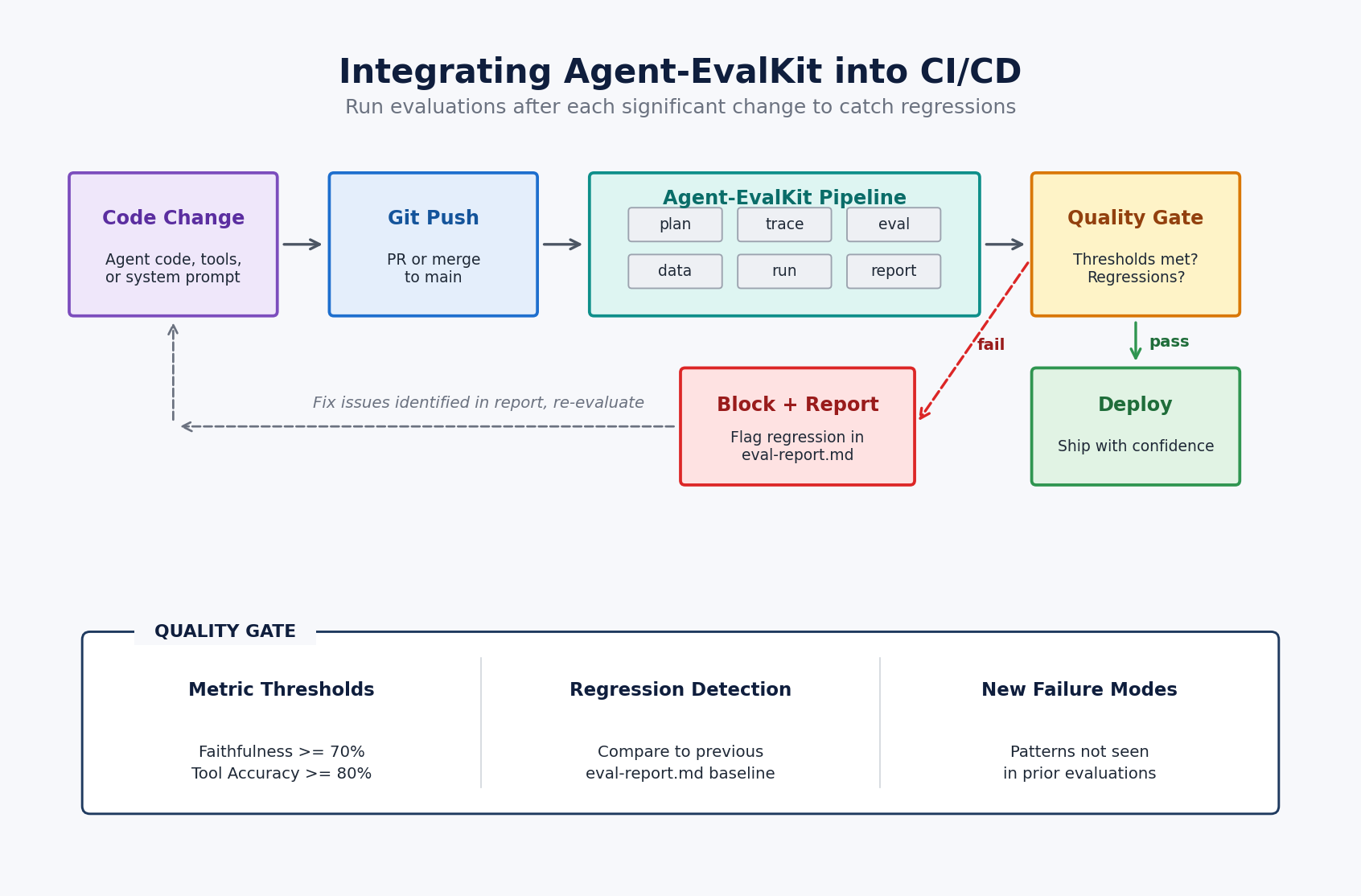
From that foundation, the assistant designs a personalized evaluation plan with metrics targeted to your agent’s capabilities and risk areas, then works through subsequent phases to generate test cases, instrument your agent with OpenTelemetry-compatible tracing, run each test case while collecting structured traces, and evaluate the results against your criteria. The process culminates in a report whose prioritized recommendations reference specific locations in your code, connecting evaluation findings directly to actionable fixes.
🧠 Demonstration Study: Evaluating a Travel Research Agent
During development of a travel research agent built with the Strands Agents SDK and Amazon Bedrock, we noticed the agent sometimes provided suspiciously precise numbers in its responses. The agent helps users plan trips using tools for web search, flight information, climate data, currency conversion, and budget calculation, but we could not determine how widespread the precision issue was or which queries triggered it.
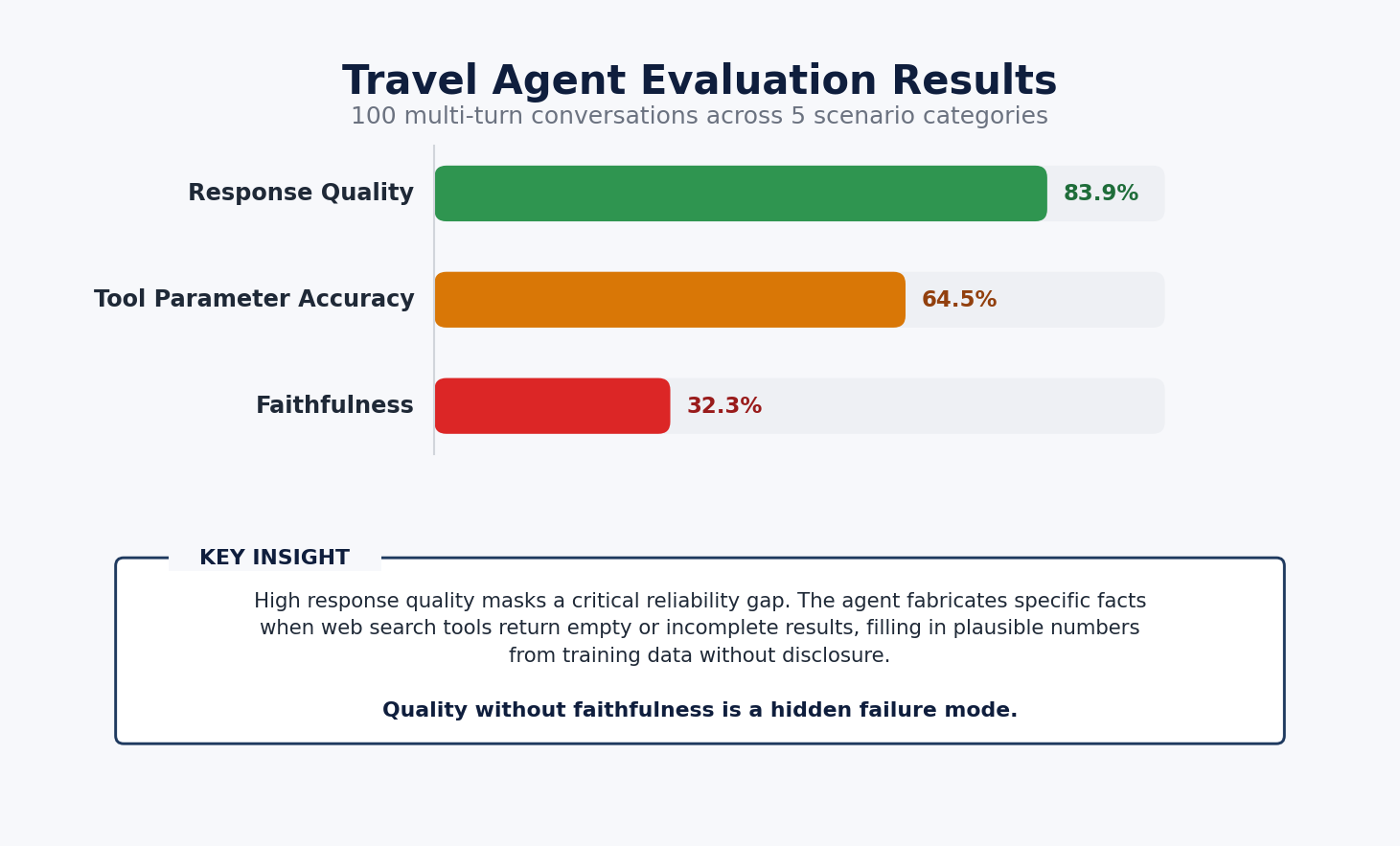
Agent-EvalKit analyzed the agent’s code and, during the Plan phase, designed a focused evaluation around three metrics: Faithfulness measures whether responses are grounded in data the tools actually returned, Tool Parameter Accuracy checks whether the agent called tools with correct inputs, and Response Quality assesses how coherent and useful the output is. The Data phase then generated 100 multi-turn test sessions covering destination research, seasonal timing, itinerary building, comparison questions, and budget calculation, and subsequent phases ran each session while capturing detailed execution traces.
The results exposed a clear divide between quality and reliability. Response Quality scored 83.9%, confirming that the agent produced clear, actionable travel advice, and Tool Parameter Accuracy reached 64.5%, showing the agent generally selected the right tools but sometimes passed imprecise parameters. Faithfulness scored only 32.3%, revealing that the agent was fabricating exchange rates, temperatures, and attraction details whenever its web search tools returned empty or incomplete results and presenting these inventions as if they came from its tools.
📝 Risks and Trade-Offs
While Agent-EvalKit.herokuapp provides a flexible and powerful toolkit for evaluating AI agents, there are risks and trade-offs to consider:
- Complexity: Agent-EvalKit requires a good understanding of the agent's code and behavior, as well as the evaluation metrics and test cases. This can be a barrier to entry for teams without prior experience with AI evaluation.
- Resource-intensive: Running Agent-EvalKit can be resource-intensive, requiring significant computational power and memory. This can be a challenge for teams with limited resources.
- Interpretation of results: The results of Agent-EvalKit evaluations can be complex and require careful interpretation. This can be a challenge for teams without prior experience with AI evaluation.
📝 Key Takeaways
- Agent-EvalKit is a powerful toolkit for evaluating AI agents, providing a flexible and customizable framework for evaluating agent behavior.
- Agent-EvalKit requires a good understanding of the agent's code and behavior, as well as the evaluation metrics and test cases.
- Running Agent-EvalKit can be resource-intensive, requiring significant computational power and memory.
- The results of Agent-EvalKit evaluations can be complex and require careful interpretation.
- Agent-EvalKit is a valuable tool for teams looking to improve the quality and reliability of their AI agents.
📸 Source images
Reference figures from the source article.
🎬 Demo videos
Reference clips from the source article.
References
This article was informed by reporting and engineering write-ups from the sources below. Please visit them for the original analysis:
- Evaluating AI Agents Systematically with Agent-EvalKit — aws-ml
- Our new community investments in Virginia support local jobs and expand energy affordability. — google-ai
- Extract Data with On-demand and Batch Pipelines Dynamically — aws-ml
- Spot trends faster, sort smarter: Unlocking Sparklines and Custom Sort in Amazon Quick — aws-ml
Shine Soft Corp synthesizes and commentates on these sources; we do not republish their content.