The AI Token Trap: Why Your AI Costs Explode Faster Than You Expect (And How to Avoid It)
AI-assisted, human-edited
This article was drafted with the help of large language models and reviewed by a Shine Soft Corp engineer before publication. Facts, citations, and code samples were verified against the linked sources. All opinions and editorial direction belong to the editor.
Learn how to avoid the AI token trap and reduce enterprise AI costs with practical optimization strategies
The AI Token Trap: Why Your AI Costs Explode Faster Than You Expect (And How to Avoid It)Learn how to avoid the AI token trap and reduce enterprise AI costs with practical optimization strategies

Intro
Everyone talks about AI capabilities.
Few people talk about AI economics.
The biggest challenge in enterprise AI isn't building an LLM-powered product anymore.
It's paying for it.
Many organizations discover this only after deployment when thousands—or millions—of prompts begin flowing through their systems. Token usage grows silently until monthly invoices become one of the largest cloud expenses. Recent enterprise experiences have highlighted how quickly AI consumption costs can escalate when adoption exceeds expectations. ([Medium][1])
What is a Token?
Explain visually
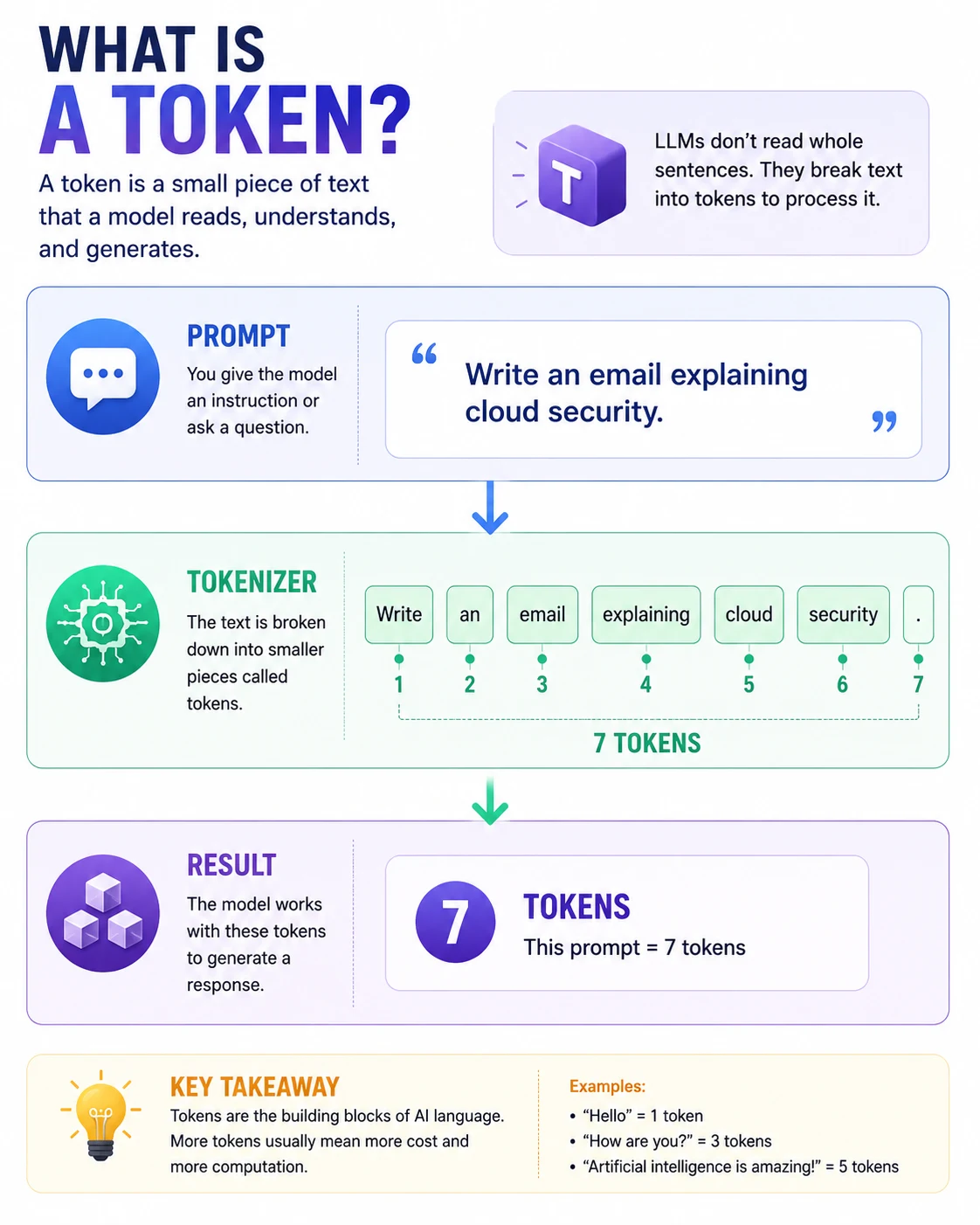
flowchart TD
A["📝 Prompt<br/><b>Write an email explaining cloud security.</b>"]
--> B["⚙️ Tokenizer"]
B --> C["Write"]
C --> D["an"]
D --> E["email"]
E --> F["explaining"]
F --> G["cloud"]
G --> H["security"]
H --> I["."]
I --> J["✅ Total: 7 Tokens"]
style A fill:#2563eb,color:#fff,stroke:#1e40af,stroke-width:2px
style B fill:#7c3aed,color:#fff,stroke:#5b21b6,stroke-width:2px
style C fill:#ecfeff,stroke:#06b6d4
style D fill:#ecfeff,stroke:#06b6d4
style E fill:#ecfeff,stroke:#06b6d4
style F fill:#ecfeff,stroke:#06b6d4
style G fill:#ecfeff,stroke:#06b6d4
style H fill:#ecfeff,stroke:#06b6d4
style I fill:#ecfeff,stroke:#06b6d4
style J fill:#22c55e,color:#fff,stroke:#15803d,stroke-width:2px
Infographic

Why AI Costs Grow Non-Linearly
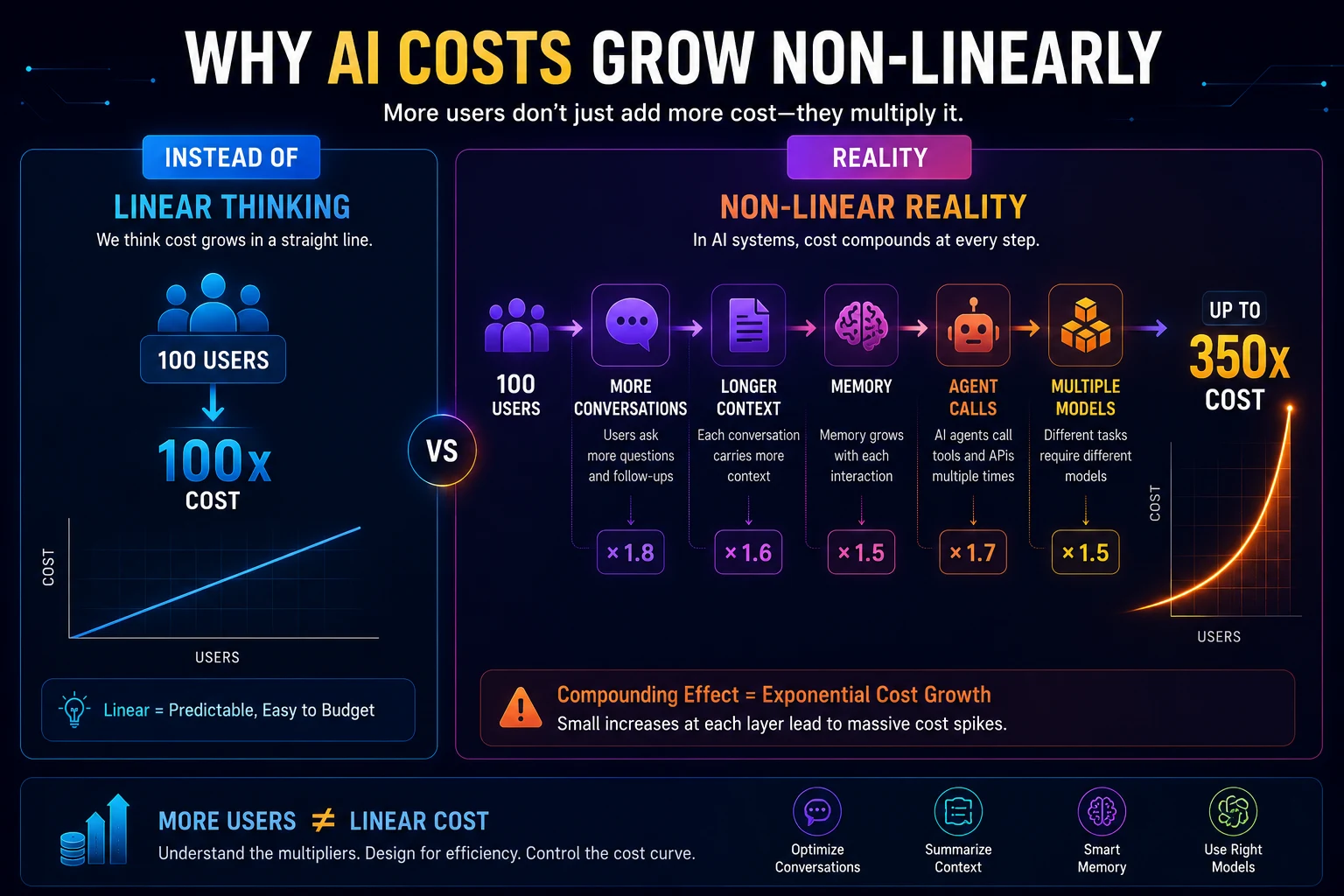 Explain
ExplainInstead of
100 users
↓
100x cost
Reality becomes
 ---
---Enterprise Cost Explosion
Table
| Feature | Traditional App | AI App |
|---|---|---|
| Login | Fixed | Fixed |
| Search | Cheap | Moderate |
| Chat | None | Expensive |
| Memory | Small | Growing |
| Documents | Minimal | Large Context |
| Agents | None | Multiple LLM Calls |
The Four Token Traps
1. Context Window Explosion
Each new message increases prompt size.
flowchart TD
A["👋 Initial Prompt<br/><b>Hello</b>"]
A --> B["📦 ~20 Tokens"]
B --> C["💬 Ongoing Conversation"]
C --> D["📈 ~5,000 Tokens"]
D --> E["🧠 Conversation + Long-Term Memory"]
E --> F["💸 ~30,000 Tokens"]
G["⚠️ Every new message includes previous context.<br/>Longer conversations dramatically increase token usage."]
F -.-> G
style A fill:#2563eb,color:#fff
style B fill:#0ea5e9,color:#fff
style C fill:#7c3aed,color:#fff
style D fill:#f59e0b,color:#fff
style E fill:#dc2626,color:#fff
style F fill:#991b1b,color:#fff
style G fill:#fff7ed,stroke:#f59e0b,stroke-width:2px
2. Agent Chains
One request becomes
flowchart TD
U["👤 User Request"]
P["🧠 Planner"]
R["🔍 Research Agent"]
S["🗄️ SQL Agent"]
C["💻 Code Agent"]
M["📝 Summarizer"]
F["✅ Final Response"]
U --> P
P --> R
P --> S
P --> C
R --> M
S --> M
C --> M
M --> F
style U fill:#2563eb,color:#fff
style P fill:#7c3aed,color:#fff
style R fill:#0891b2,color:#fff
style S fill:#0f766e,color:#fff
style C fill:#ea580c,color:#fff
style M fill:#16a34a,color:#fff
style F fill:#15803d,color:#fff
One user request can trigger multiple model invocations, multiplying token consumption.
3. RAG Inflation
flowchart TD
Q["❓ User Question"]
Q --> VS["🔍 Vector Search"]
VS --> D1["📄 Doc 1"]
VS --> D2["📄 Doc 2"]
VS --> D3["📄 Doc 3"]
VS --> D4["📄 ..."]
VS --> D5["📄 Doc 15"]
D1 --> CI
D2 --> CI
D3 --> CI
D4 --> CI
D5 --> CI
CI["🧩 Context Injection<br/>Thousands of Extra Tokens"]
CI --> LLM["🧠 LLM Processing"]
LLM --> A["✅ Final Answer"]
style Q fill:#2563eb,color:#fff
style VS fill:#0891b2,color:#fff
style D1 fill:#0f766e,color:#fff
style D2 fill:#0f766e,color:#fff
style D3 fill:#0f766e,color:#fff
style D4 fill:#0f766e,color:#fff
style D5 fill:#0f766e,color:#fff
style CI fill:#ea580c,color:#fff
style LLM fill:#7c3aed,color:#fff
style A fill:#16a34a,color:#fff
4. Memory Growth
flowchart TD
A["🌱 Day 1<br/><b>2 KB</b><br/>New User"]
B["💬 Day 30<br/><b>300 KB</b><br/>Conversation History"]
C["🧠 Day 365<br/><b>Several MB</b><br/>Long-Term Memory"]
D["⚠️ More Context Sent<br/>to Every LLM Request"]
E["💸 Token Usage<br/>Keeps Growing"]
A --> B
B --> C
C --> D
D --> E
style A fill:#22c55e,color:#fff
style B fill:#f59e0b,color:#fff
style C fill:#ef4444,color:#fff
style D fill:#7c3aed,color:#fff
style E fill:#991b1b,color:#fff
Persistent memory improves personalization but also increases the amount of context sent to the model if not managed carefully.
Architecture Comparison
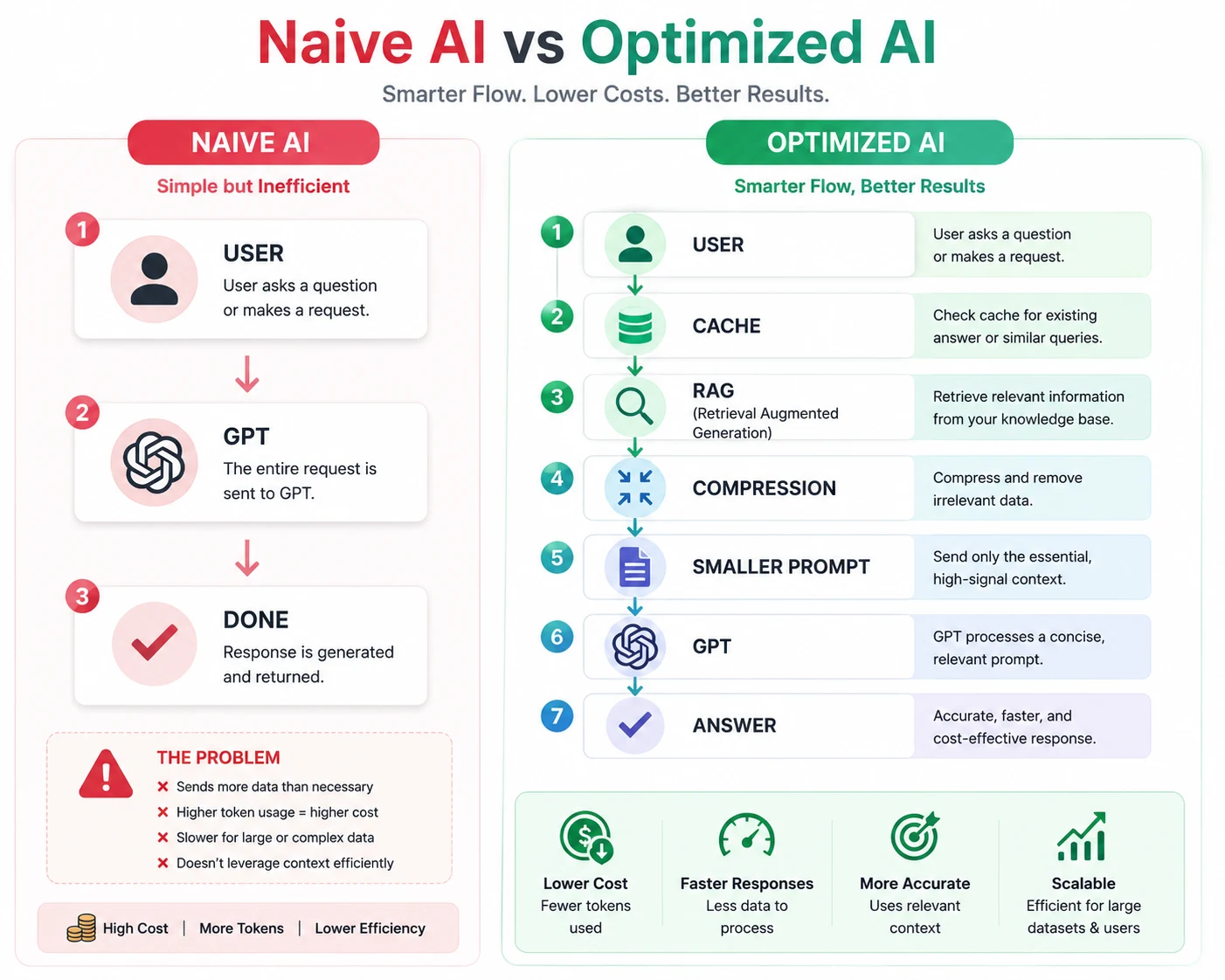
Cost Optimization Strategies
Prompt Compression
Only send necessary context.
Response Caching
Avoid repeated token generation.
Smaller Models
Not every request requires a frontier model.
Semantic Search
Retrieve only relevant information instead of entire documents.
Conversation Summaries
Replace long histories with concise summaries.
Intelligent Routing
flowchart TD
A["👤 User Question"]
A --> B{"📊 Request Complexity"}
B -->|Basic Query| C["💡 Small Model<br/>💰 Low Token Cost"]
B -->|Advanced Reasoning| D["🧠 Large Model<br/>💸 Higher Token Cost"]
C --> E["✅ Fast Answer"]
D --> E
style A fill:#2563eb,color:#fff
style B fill:#8b5cf6,color:#fff
style C fill:#22c55e,color:#fff
style D fill:#dc2626,color:#fff
style E fill:#0891b2,color:#fff
Cost Reduction Diagram

(Illustrative example rather than guaranteed savings.)
Enterprise Checklist
- Measure token usage per feature
- Monitor cost per customer
- Cache repeated prompts
- Compress conversation history
- Limit context size
- Use RAG efficiently
- Route simple tasks to smaller models
- Monitor token spikes
- Set spending alerts
- Continuously optimize prompts
Conclusion
Generative AI is changing software economics. Unlike traditional applications where infrastructure costs often scale predictably, LLM-powered systems can experience sharp increases in spending due to larger context windows, agent workflows, and growing usage. Organizations that treat tokens as a first-class engineering metric—monitoring, optimizing, and budgeting for them—will be better positioned to build sustainable AI products.